
-
-
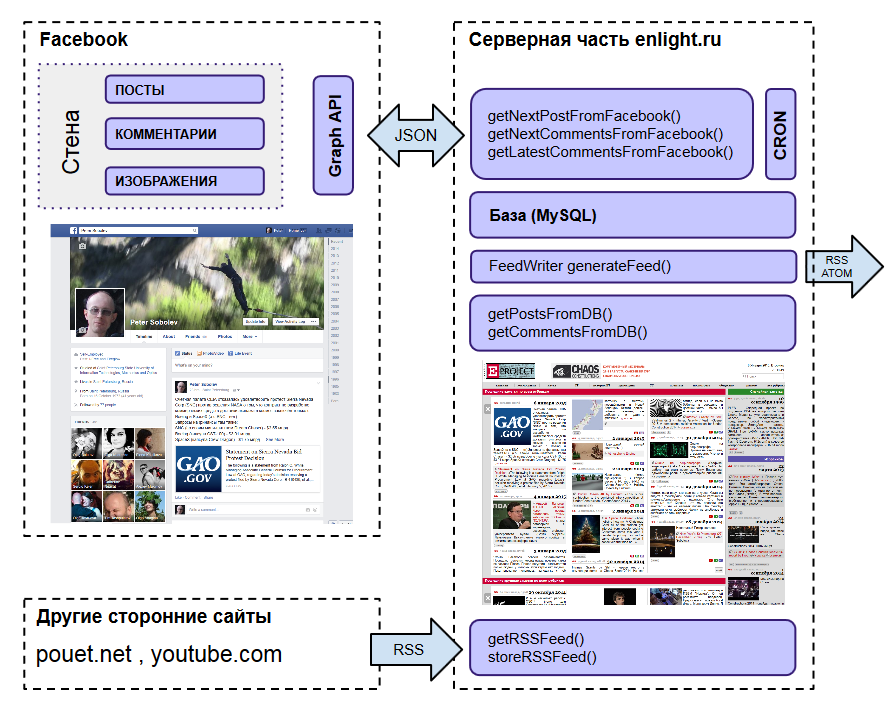 С течением времени в фейсбуке скопилось довольно много моих собственных постов и комментариев, среди которых, как ни странно, были и полезные. Несмотря на ряд удобств, которые предоставляет фейсбук, он совершенно не предназначен для хранения и поиска чего-либо на стене (timeline'e). Более того - нет никаких гарантий, что завтра всё это не пропадёт бесследно, как это можно видеть по периодически исчезающим (может на время, а может и нет) отдельным постам, отметкам на карте и пр.
С течением времени в фейсбуке скопилось довольно много моих собственных постов и комментариев, среди которых, как ни странно, были и полезные. Несмотря на ряд удобств, которые предоставляет фейсбук, он совершенно не предназначен для хранения и поиска чего-либо на стене (timeline'e). Более того - нет никаких гарантий, что завтра всё это не пропадёт бесследно, как это можно видеть по периодически исчезающим (может на время, а может и нет) отдельным постам, отметкам на карте и пр.
ПОЛУЧЕНИЕ ДАННЫХ
Подробно весь процесс расписывать не буду - он не очень сложен, да и примеры в сети доступны (только осторожнее с документацией - она у фейсбука, как водится, не всегда полна и актуальна - пользуйтесь http://stackoverflow.com ). Остановлюсь лишь на некоторых существенных моментах.
По существу, задача состоит следующих частей:
1.Разовое получение всех текстов и картинок (как иллюстраций к постам, так и генерируемых фейсбуком миниатюр для ссылок) начиная с первого моего поста в фейсбук (с 2009 года) и помещение их в базу. Это, в сумме, более тысячи постов. По этой причине получить всё это можно только порциями - сразу фейсбук такой объем данных не отдаст.
2.Получение текстов и картинок новых постов. Здесь достаточно периодически запрашивать несколько последних постов и помещать в базу новые из них (id которых там ещё нет).
3.Получение старых комментариев к постам.
4.Получение новых комментариев к постам (учитывая, что к старым постам комментарии появляются редко, а к новым довольно часто, 3 и 4 имеет смысл разделить)
5.В идеале следовало бы ещё отслеживать изменения старых постов и комментариев, но особой практической необходимости в этом пока нет.
Для работы с фейсбуком из php требуется подключение их библиотеки и создание пустого приложения в самом fb ( о получении токена, дающего права на доступ к данным своего аккаунта, я уже писал ранее - к сожалению по-прежнему его необходимо обновлять каждые 60 дней)
Инициализация всего этого дела выглядит так:
[...]
$fb_app_id = '...'; // берётся из настроек созданного FB приложения
$fb_app_secret = '...'; // берётся из настроек созданного FB приложения
$fb_access_token = '...'; // тот самый токен, который вам придётся регулярно получать и прописывать здесь ручками каждые 60 дней.
$fb_graph = '/your_user_id/feed'; //стандартное начало запроса к graph api
// обратите внимание, что до мая 2015 года вместо your_user_id можно было использовать your_user_name. А теперь нельзя - возвращается ошибка 'Cannot query users by their username'. Узнать your_user_id можно, открыв в браузере http://graph.facebook.com/your_user_name
require_once('php/facebook.php');
[...]
Далее сами запросы. Что-то вроде:
$fb_graph = $fb_graph . '?limit=' . $limit . '&until=' . $current; // последние несколько ваших постов
$fb_graph = $id . '/comments?limit=1000'; // комментарии к посту $id ("aid_oid")
$fb_graph = $id . '/'; // данные о конкретном объекте $id (к примеру, изображении)
[...]
$facebook = new Facebook(array('appId' => $fb_app_id, 'secret' => $fb_app_secret,));
$facebook->setAccessToken($fb_access_token);
$data = $facebook->api($fb_graph); // собственно, запрос
В результате возвращаются данные в json, примерно вида:
{
"data": [
{
"id": "aid_oid",
...
},
...
],
"paging": {
"cursors": {
"after": "aa",
"before": "bb"
},
"next": "https://graph.facebook.com/....."
}
}
где id состоит из двух частей - идентификатора того, кто создал объект (aid), подчеркивания, идентификатора самого объекта (oid).
Деление "id" на две части здесь неслучайное. К примеру, в самом фейсбуке ссылка на конкретный пост (если кликаете на его дату) имеет вид:
https://www.facebook.com/your_user_id/posts/oid
Т.е. здесь вторая половина id используется отдельно (первая подразумевается, т.к. указано your_user_id соответствующее aid).
Посты могут быть разных типов (status, photo, link, video, question и пр. ) - взависимости от того, как вы их создаёте в фейсбуке. Соответственно, для разных типов возвращаются несколько разные поля.
Если данных слишком много (это неизбежно. если нужно достать все посты, да даже к одному посту может быть более 25 комментариев), то в конце пакета появляется указание, как получить следующую порцию ("next"). Или предыдущую, если нужно вернуться назад. Если возвращены все имеющиеся данные, "after" и "before" будут присутствовать всё равно (но не будет "next"/"previous").
При необходимости можно получать данные с или до определённой даты ("since", "until") или определённое их количество с конкретного места ("offset", "limit").
Например : "aid_oid/comments?limit=100"
Конечно, "limit" указанный выше некоторого значения (по идее, зависит от запроса) всё равно отдаст только фрагмент.
Когда я создавал первоначальную базу, то запрашивал пачками по 20 постов в минуту, сохраняя в базе значение "next" и начиная следующий запрос с него (вероятно, можно было бы забирать больше и чаще, но лучше перестраховаться).
В дальнейшем данные запрашивались (и запрашиваются) уже только раз в час.
Ещё раз замечу, что посты в фейсбуке действительно пропадают. Т.е. реальна ситуация, когда вы получаете id очередного поста, но этого поста не существует - в фейсбуке в него не попасть, а попытка получить данные через Graph API даёт "GraphMethodException: Unsupported get request" (причем, что смешно, запрос комментариев к такому посту через Graph API к ошибке не приводит).
Чтобы вытаскивать из своего таймлайна не только текст, но и изображения (те, что опубликованы в том же таймлайне, т.к. с альбомами отдельная песня), при получении токена кроме export_stream надо еще предоставить приложению право user_photos. Иначе возникнет загадочная ошибка "Unsupported get request" GraphMethodException 100 (и что им мешало возвращать логичное "Access denied"?)
Кроме того, данные об изображении не являются частью поста. Т.е. их нужно вытаскивать отдельно. В этих данных будут содержаться url картинок в нескольких разрешениях. При этом, картинка в оригинальном разрешении вовсе не ["source"] (как можно подумать), а ["images"][0]. По-видимому ["source"] - это то, что показывается пользователю при клике на пост.
Второй момент, касающийся тех же изображений в таймлайне: id поста с изображением и id самой фотографии - не связанные между собой вещи.
Теперь, что касается получения комментариев:
Несмотря на то, что комментарии (и лайки) к посту содержатся в возвращаемых для него данных, они там не все. Т.е., после получения данных о посте необходимо отдельно вытаскивать комментарии к нему.
По-правильному, это нужно делать постранично, также как и чтение таймлайна. Однако, если вы точно знаете, что комментариев не будет очень много, можно обойтись и одним запросом "/id_поста/comments?limit=1000". Без указания limit (т.е. по умолчанию) стандартно возвращается 25 комментариев. С указанием limit=1000 как минимум 180 штук вытаскиваются точно).
id комментария имеют такой же составной вид, как и id постов: oid_cid (oid - id поста, cid - id комментария для этого поста)
С комментариями, в отличие от постов, есть очевидный ньюанс - они имеют свойство появляться в произвольных местах (в то время, как посты всегда последовательны :). По этой причине получение и сохранение в базе комментариев происходит параллельно двумя способами:
1.Проходим последовательно по всем постам (имеющим отношение к фейсбуку) в базе и для каждого получаем из фейсбука и сохраняем в базу комментарий, если такого (с таким же oid_cid) там ещё не было . Причём, первый раз делаем всё это по-быстрому - раз в две минуты на пост, т.е. за несколько суток, чтобы первоначально наполнить базу. А потом раз в двадцать минут - исходя из предположения, что к старым постам комментарии появляются очень редко и спешки их обновлять особой нет.
2.Параллельно раз в двадцать минут обновляем комментарии к случайному посту из десяти самых свежих. В предположении, что к свежим постам комментарии появляются довольно часто, но к какому - заранее неизвестно.
Заодно обновляем также счётчики comments, likes и shares для данного поста. Чтоб были.
Теоретически, новые комментарии можно было бы запрашивать через FQL (это было бы проще и логичнее), но FQL в фейсбуке приговорён и его прикроют в августе 2016-го, поэтому смысла заморачиваться особо нет.
Кстати, в отличие от поста, в комментариях не хранятся preview изображений для ссылок (точнее, где-то хранятся конечно, но через API не возвращаются). Также не возвращается признак того, что комментарий был отредактирован (равно как и дата его изменения).
ПРЕДСТАВЛЕНИЕ ДАННЫХ НА САЙТЕ
Раз уж было решено публиковать всё на общедоступном сайте, логично позаботиться о каком-то минимуме удобств.
О хранении данных говорить особо нечего - там, по сути, три таблицы - для постов, для комментариев и для хранения текущих состояний для "next". Разве что, скажу пару слов про рубрики.
Просмотрев свои посты, я выделил десять тем, по которым публиковал записи чаще всего: авиация и космонавтика, наука, информационные технологии, история вычислительной техники. демосцена, фестиваль Chaos Constructions, прочитанное (книжки), просмотренное (нетехнические фильмы и видео), разное.
Важно было сделать так, чтобы для появления заметок на сайте не требовалось никаких дополнительных действий вне фейсбука (т.к., по опыту, рано или поздно станет лень этим заниматься). Соответственно:
а) Рубрики назначаются путём включения в конец поста обратного апострофа и соответствующих каждой из рубрик букв (например, `id означает, что заметку надо опубликовать в рубриках IT и демосцена). В базе это сохраняется в виде SET, а достаётся, соответственно FIND_IN_SET().
б) Заголовки автоматически формируются в формате "вчера, 08:20 30 декабря 2014" (поскольку регулярное придумывание внятных заголовков - весьма утомительная вещь).
Лирическое отступление:
К слову, фейсбук хорош в деле вычленения из сайта (при публикации ссылки) изображения и фрагмента текста, описывающего ссылку. Особенно, когда на сайте-источнике не указаны соответствующие Opengraph тэги. Google+ и ВКонтакт в этом отношении не идут ни в какое сравнение.
Есть, правда, один неочевидный момент. Фейсбук кэширует анализируемый контент. Т.е., если опубликовать в посте ссылку на сайт, который в эту секунду как-то сломан (скажем, в нём отвалились все картинки) или когда сломан сам фейсбук (и не может нормально получить данные с работающего сайта, что бывает нередко), то текст и/или картинка для поста могут не сгенерироваться. Причём, даже когда всё уже починится, последующие попытки постинга будут давать тот же результат на протяжении часов, если не суток. Так вот, этот кэш у фейсбука можно сбросить, один раз просмотрев конкретную проблемную ссылку его debugger-ом.
Поиск.
Стандартный полнотекстовый поиск MySQL. Вполне годен, если не считать ограничения минимальной длины строки в пять, если не ошибаюсь, символов. Ну и отсутствия морфологии (заморачиваться с которой для данного проекта явно излишне).
Поиск происходит по всем рубрикам, либо по одной текущей / выбранной.
Теперь, что касается, собственно, выводимых страниц. Существенной особенностью является тот факт, что подавляющее большинство постов имеют очень небольшой размер. Обычно это ссылка, плюс очень короткий комментарий к ней (если он вообще есть) + маленькая картинка, вытащенная с сайта фейсбуком (обычно есть) + короткий фрагмент текста, также вытащенный с сайта фейсбуком (тоже обычно есть).
Если выводить такие посты обычной вертикальной лентой, на большинстве современных экранов это будет выглядеть довольно удручающе (средний пост целиком уместится в одну очень длинную строку текста.
Поэтому, изначально было решено сделать главную страницу (и страницы рубрик) в формате "газеты", когда колонок несколько, в результате чего посты выглядят более адекватно, да и в целом страница смотрится лучше - можно одним взглядом охватить множество последних заметок (плюс обычный постраничный просмотр ленты, при нажатии "ещё".).
Однако, такой "газетный" подход потенциально создаёт две проблемы. Во-первых, если экран всё же оказался узким, несколько колонок будут выглядеть неуместно и малочитаемо (а ведь адекватное отображение на мобильных устройствах тоже необходимо). Во-вторых, нужно обеспечивать примерно одинаковую высоту колонок, чтобы не было больших пустых областей. Всё это замечательно, на мой взгляд, решается использованием CSS свойств column-*.
Всё это замечательно, на мой взгляд, решается использованием CSS свойств column-*.
Для колонок фиксируется ширина (а не количество). При уменьшении ширины экрана колонок становится меньше. При этом текст автоматически равномерно распределяется между ними. Меню реализовано аналогичным образом.
Пока что в браузерах эти column-* сыроваты, но если не усложнять верстку блоков внутри колонок, глюки остаются в допустимых границах.
Новости на главной странице идут двумя блоками - в первом несколько самых свежих, по всем рубрикам. Во втором - тоже самое, но выводятся только те, размер которых больше заданного. Таким образом, наиболее существенные посты долго висят на главной.
В правой части 20% пространства отведено под отдельную колонку, где выводятся случайные заметки (не менее определённого объема) и одна-две явным образом заданных, индивидуально для каждой рубрики.
При уменьшении ширины экрана, сначала уменьшается число колонок, а затем, если экран совсем уж узкий, правая колонка перестраивается вниз (через CSS @media). В результате, получается совсем уже мобильная версия сайта.
Дополнительно в верхней части раздела посвященного Chaos Constructions показываются последние видео с соответствующего канала Youtube, а в разделе Демосцена - ссылки на последние опубликованные на pouet.net работы. И то и другое, через небольшие промежутки времени, забирается с Youtube и Pouet по RSS и сохраняется в базе (дёргать RSS у youtube'a при каждом посещении раздела нельзя - он в этом случае довольно быстро перестаёт отдавать feed для данного ip, на сутки или двое).
Изображения в постах выводятся:
В блоках с новостями на главной и в подразделах (миниатюры) - в фиксированном маленьком размере, таком же, как в таймлайне в фейсбуке.
В правой колонке - адаптивно, но не более 130 пикселов шириной: { width: 100%; height: auto; max-width: 130px; }
На странице конкретной заметки - берётся изображение максимального разрешения с возможностью уменьшения, но не увеличения: { height: auto; max-width: 100%; }
ЧТОБЫ ДВА РАЗА НЕ ВСТАВАТЬ
Ещё до того, как появился и стал популярным Facebook, я регулярно публиковал (с 1997 года) короткие заметки и отдельные статьи / интервью с разными людьми - проект назывался IB/NEWS (Infused Bytes Online). Всё это работало на древнем скрипте и хранилось в html файлах. Поскольку всё равно уже была проведена вышеописанная работа, не так сложно было распарсить весь этот html, пометить заметки тэгами и поместить в ту же базу (поставив permanent redirect на новые url), заодно избавившись от древних скриптов. Аналогично я поступил и со своим ЖЖ - http://cr_it.livejournal.com.
Также прикручена простая форма для добавления и редактирования записей в базе (любых - в т.ч. и импортированных из фейсбука).
Помимо просмотра всех заметок на сайте, к ним организован доступ по RSS (используется FeedWriter ) - как общей лентой, так и раздельно по рубрикам.
Надо отметить, что в первой версии сайта на главной странице выводилось не два новостных блока, а много (блоки последних заметок по каждой рубрике). Поэтому была реализована возможность скрывать любой из блоков (крестик слева) и восстанавливать (иконка справа, которая появляется на красном заголовке). При этом текущее состоянии записывается в localStorage, т.е. запоминается для данного браузера.
Также на всех страницах генерируются opengraph meta тэги (они определяют, каким образом будут выглядеть заметки при расшаривании в соцсети и другие места).
 "Finally, we come to the instruction we've all been waiting for – SEX!" / из статьи про микропроцессор CDP1802 / В начале 1970-х в США были весьма популярны простые электронные игры типа Pong (в СССР их аналоги появились в продаже через 5-10 лет). Как правило, такие игры не имели микропроцессора и памяти в современном понимании этих слов, а строились на жёсткой ...далее
"Finally, we come to the instruction we've all been waiting for – SEX!" / из статьи про микропроцессор CDP1802 / В начале 1970-х в США были весьма популярны простые электронные игры типа Pong (в СССР их аналоги появились в продаже через 5-10 лет). Как правило, такие игры не имели микропроцессора и памяти в современном понимании этих слов, а строились на жёсткой ...далее