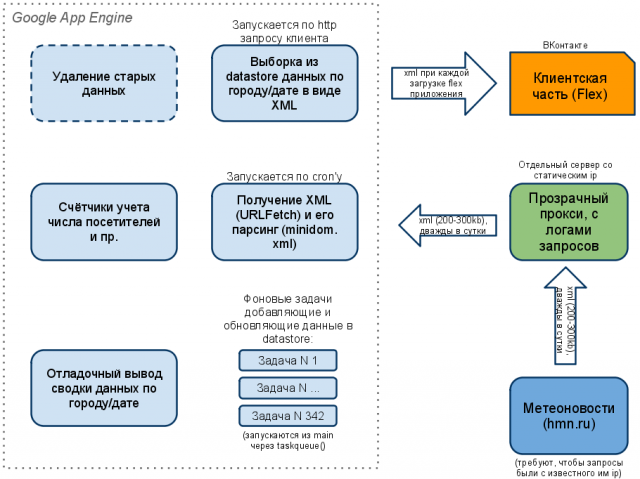
13 августа 2009, 16:12 (6179 дней назад, №8772)Пример разработки под Google App Engine (погода)
На примере
приложения показывающего прогноз погоды, захотелось попробовать, что представляет собой
Google App Engine (а заодно - Python). Клиентская часть (реализация на Flex) достаточно примитивна - при выборе города посылается запрос к серверной части и та возвращает XML пакет с прогнозом на несколько дней, который показывается в виде текста и картинок. Текущий город запоминается у пользователя в SharedObject.

Более интересно поговорить о серверной части.
Задача для неё заключается в следующем:
Два раза в сутки мы должны забирать XML файл размером примерно 300 кб (прогноз по сотням городов на 4 дня), парсить его и помещать в базу данных. После чего отдавать клиенту данные для нужного города/даты. Достаточно важный момент - прогноз постоянно уточняется, поэтому если мы получаем данные за дату для которой они уже есть в базе, нужно их обновить.
Кроме того, особенностью сервиса предоставляющего информацию о погоде (кстати, похоже это характерно для отечественных сервисов) является ограничение по ip - данные можно забрать только с ip, который есть у них в списке. Поскольку GAE состоит из сотен серверов и неизвестно, на каком в данный момент времени будет запущен скрипт, ip постоянно меняется. Пришлось сделать простой прокси на своем сервере, единственная задача которого - проброс запроса к сервису погоды и пересылка полученного оттуда XML файла. Т.к. это происходит лишь два раза в сутки, особых проблем и нагрузок не возникает.
Первая и главная трудность, с которой пришлось столкнуться - так называемые "квоты" GAE на все, что только можно. На процессорное время, на число и длительность HTTP запросов, на объем передаваемых и принимаемых по HTTP данных, на число запросов к хранилищу и т.п. Причем, есть суточные квоты, которых при правильном программировании в принципе хватает и бесплатных (их можно увеличить, включив биллинг) и есть "по-минутные" квоты, с которыми все серьезнее. Основной смысл по-минутных квот - не позволять приложению потреблять ресурсы в ущерб другим приложениям, которые работают в данный момент на том же сервере. Квоты эти чрезвычайно жёсткие, из-за чего подход к разработке принципиально меняется. Нужно постоянно думать, как уместиться в ограничения, помнить какие операции считаются дешевыми, а какие дорогими (в прямом и переносном смысле). Процесс живо напомнил мне программирование на ассемблере для восьмибитного MOS6510 (56 команд, три регистра) на Commodore 64 :)
![]()
![]() Возьмём, к примеру, простую, казалось бы, операцию - получение XML файла, его парсинг (сделал через minidom.xml, хотя эффективнее, видимо, было бы через elementstree) и помещение данных в хранилище. На PHP/MySQL и традиционном хостинге мы могли бы просто в цикле вставлять получаемые данные INSERT'ом в базу. Здесь, увы, халява не пройдёт - уже через пару десятков таких вставок будет превышена по-минутная квота на api_calls к хранилищу и приложение будет прибито с exception'ом "DeadlineExceed".
Возьмём, к примеру, простую, казалось бы, операцию - получение XML файла, его парсинг (сделал через minidom.xml, хотя эффективнее, видимо, было бы через elementstree) и помещение данных в хранилище. На PHP/MySQL и традиционном хостинге мы могли бы просто в цикле вставлять получаемые данные INSERT'ом в базу. Здесь, увы, халява не пройдёт - уже через пару десятков таких вставок будет превышена по-минутная квота на api_calls к хранилищу и приложение будет прибито с exception'ом "DeadlineExceed".
До последнего времени эта проблема решалась в GAE очень извращёнными способами - процедура разбивалась на несколько этапов, через запуск скрипта по крону с разными параметрами.
К счастью, совсем недавно появилось нормальное решение - сервис TaskQueue. Идея в том, что можно запускать кусок кода так, что он будет выполняться в фоне. В цикле создаём кучу задач (по одной на каждый город) и каждая из этих задач независимо от других занимается записью данных по погоде в этом городе в datastore. GAE сам решает, на каких серверах какая задача выполняется. Можно зафиксировать минимальный промежуток времени между запуском каждой задачи и таким образом растянуть процесс, избегая превышения по-минутных квот по CPU time.
for cnode in cnodes:
...
dbentry.tt = entry['tt']
dbentry.w = entry['w']
...
taskqueue.add(url='/putentry2db', params={'dbentry': pickle.dumps(dbentry)})
class PutEntry2DB(webapp.RequestHandler):
def post(self):
d = self.request.get('dbentry')
dbe = pickle.loads(str(d))
...
res = dbe.put()
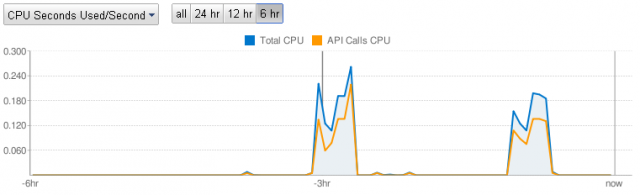
На графике видно, что хотя нагрузка значительная (по сравнению с крохотными холмиками, означающими запросы на чтение из datastore), однако процесс растянут во времени. Тот факт, что вершина не плоская, отражает текущую загрузку серверов Google'a и то, что данные по каждому из четырёх дней обрабатываются у меня отдельно (т.е. на графике скрипт вызывался по крону восемь раз - по четыре на каждое обновление прогноза).
API Calls CPU означает в данном случае именно время затраченное на обращение к datastore ( там get() и put() ) и обращение к taskqueue.add()
Итак, допустим, данные в хранилище мы поместили и они там лежат в виде:
class DBEntry(db.Model):
dtf = db.DateProperty(indexed=True) # на какую дату прогноз
c = db.IntegerProperty(indexed=True) # city id
t = db.StringProperty() # Название города
...
tf = db.ListProperty(long,indexed=False) # Температура от
tt = db.ListProperty(long,indexed=False) # Температура до
...
dtc = db.DateTimeProperty(auto_now_add=True,indexed=True) # когда сделана запись
Теперь задача номер два - надо отдавать требуемые данные Flex клиенту. По-правильному, вероятно, надо было бы делать это в виде бинарного AMF3 (PyAMF вполне работает с GAE), но я на этот момент уже обжёгся на квотах (на кодирование в AMF будет уходить ощутимый CPU time, полагаю) и решил отдавать обычный XML.
Для начала попробовал просто читать из datastore:
query = db.GqlQuery("SELECT * FROM DBEntry WHERE c = :1 AND dtf >= :2 AND dtf <= :3",c,date_msk_since,date_msk_till)
...
results = query.fetch(10)
но эти чтения оказались весьма дорогими. Пришлось делать по-правильному, кэшируя запросы для одинаковых городов и дат через memcache.
Разница получилась очень ощутимая:
Из datastore:
575ms 1983cpu_ms 1620api_cpu_ms
401ms 378cpu_ms 210api_cpu_ms
300ms 345cpu_ms 210api_cpu_ms
505ms 1927cpu_ms 1620api_cpu_ms
Из кэша:
24ms 31cpu_ms
52ms 22cpu_ms
20ms 25cpu_ms
23ms 26cpu_ms
(во втором случае api_cpu нет, т.к. нет обращения к datastore)
Основная функциональность в итоге достигнута. Но захотелось какой-то минимальной статистики. И это - слабая сторона GAE. Дело в том, что datastore - нереляционная база данных. Невозможно выбирать данные из нескольких "таблиц" связанных по какому-то свойству. Не существует агрегатных функций (вплоть до того, что невозможно узнать сколько записей в хранилище - разве что выбрав их все).
Если нужна любая статистика, её надо считать не тогда, когда данные уже есть, а в процессе записи данных в datastore. Т.е. если хочется узнать число запросов прогноза, нужно сделать счетчик, и при каждом обращении увеличивать его значение в datastore. Но это в теории. На практике такая операция (постоянное чтение-запись одной и той же записи в datastore) приведёт все туда же - к превышению квот. Выход из этого положения в использовании т.н. sharded counters. Идея в том, чтобы не мучать одну и ту же запись, а создать их, скажем, десяток и каждый раз увеличивать случайную запись из этого десятка. Тогда GAE сможет распараллелить процесс. Само собой, чтобы узнать значение счётчика, придется вытащить все эти десять значений и сложить. Но это дешевая операция, к тому же редкая.
Вообще, специфика datastore создаёт множество препятствий. К примеру, нет способа удалить все данные (если решили начать заново или, скажем, изменить модель данных). Придется удалять по одной записи, со всеми вышеописанными неприятностями (т.е. в цикле это делать не выйдет - квоты сразу превысим). Даже если у вас накопилось всего каких-нибудь 10 тысяч записей - это уже серьезная проблема.
Нельзя просмотреть более 1000 записей подряд (в терминах SQL: нельзя указать для LIMIT больше 1000). Собственно понятно, что это все те же квоты для равномерного распределения нагрузки, только в завуалированном виде. В последнем roadmap'е вот грозятся ввести курсоры, чтобы как-то жить с этим ограничением.
Язык запросов (GQL) только на очень поверхностный взгляд напоминает SQL. На самом деле там куча ограничений, в WHERE далеко не все операции можно сочетать. Выбираются всегда все свойства записи (" SELECT * " указывается скорее для красоты).
Помимо этих проблем, обусловленных архитектурой системы (её распределенностью, в первую очередь) есть и просто недоработки. Казалось бы - сервис Google'a, уж наверное там с поиском должно все быть просто, удобно и мощно. Увы. Пока нормального решения просто нет. Также как нет, например, сервиса для хранения больших файлов (хотя это уже вот-вот обещают).
Также, что касается админки - порядочно сделано для того, чтобы можно было следить за нагрузкой, но почти ничего для работы с тем же datastore.
Отдельно надо отметить нестабильность системы. Речь даже не столько о периодических отказах сервисов (они не так уж часты и вполне допустимы, учитывая статус GAE), сколько о совершенно непредсказуемой реакции системы на совершенно одинаковые действия. Один и тот же скрипт, ежедневно забирающий практически одинаковые файлы и помещающий в datastore одинаковое количество очень похожих данных может то работать без ошибок, создавая небольшую нагрузку, то вдруг превышать допустимый CPU time, выдавать различного рода TransientError, MemoryError, Timeout и прочее, которые в группе поддержки GAE, как правило, никак не комментируются (т.е. люди часто спрашивают, но конкретно по таким вопросам ответов не получают).
Общий рекомендуемый подход, насколько я смог его понять из отдельных писем разработчиков GAE, состоит в том, что необходимо обрабатывать все теоретически возможные exception'ы во всех теоретически возможных местах их появления и в случае чего (сбой при чтении или записи в datastore, к примеру) повторять попытку.
Стоит сказать пару слов про SDK. SDK существует под Windows, MacOS, Linux и эмулирует datastore, доступные в GAE библиотеки, веб сервер. Кроме него надо еще поставить Python 2.5 и (уже по вкусу) - Eclipse с плагином PyDev (настройка всего этого дела - процесс не совсем тривиальный. Кто будет ставить, это прочтите). SDK, в принципе, достаточно близко повторяет функциональность GAE, но админка там другая (и ведёт себя иначе), а, скажем, функциональность связанная с TaskQueue вообще реализована лишь частично (созданные задачи надо запускать руками, нажимая кнопку Submit. Особенно радует, когда это надо сделать, скажем, 300 раз подряд :)
Всё это ограничивает круг разработчиков под GAE откровенными маньяками. Вывод я бы сделал такой: перспективно (и всё равно всё к этому придёт) но пока слишком сыро.
P.S. По-русски про GAE можно почитать здесь и здесь (многое уже устарело, но для начала полезно).


 "Finally, we come to the instruction we've all been waiting for – SEX!" / из статьи про микропроцессор CDP1802 / В начале 1970-х в США были весьма популярны простые электронные игры типа Pong (в СССР их аналоги появились в продаже через 5-10 лет). Как правило, такие игры не имели микропроцессора и памяти в современном понимании этих слов, а строились на жёсткой ...далее
"Finally, we come to the instruction we've all been waiting for – SEX!" / из статьи про микропроцессор CDP1802 / В начале 1970-х в США были весьма популярны простые электронные игры типа Pong (в СССР их аналоги появились в продаже через 5-10 лет). Как правило, такие игры не имели микропроцессора и памяти в современном понимании этих слов, а строились на жёсткой ...далее