
-
-
При создании различных лент новостей и колонок онлайн газет, web дизайнеры и программисты сталкиваются с ситуацией, когда в тексте попадается очень длинное слово (синхрофазотрон, http://www.enlight.ru/camera/117/index.html, и т.п.). Браузер при форматировании разбивает текст в тех местах, где есть пробелы (дефисы). Длинные слова при этом остаются нетронутыми, что часто приводит к "разъезжанию" ячеек таблицы, неаккуратному внешнему виду. Каким образом можно решить эту проблему?

стандартное форматирование текста
(перенос по пробелам)
Первое, что обычно приходит в голову - заранее отформатировать текст с учетом предполагаемой ширины колонки (например - php/perl/python скриптом) и выдать его браузеру уже построчно (с <br> после каждой строки). Такой подход редко приводит к желаемому результату, поскольку необходимо заранее, с точностью до пиксела знать ширину ячейки в которую будет выведен текст и ширину каждого символа в строке текста. Даже если предположить, что ширина таблицы и ячеек заданы в пикселах, все равно - разнообразие точек зрения браузеров на виды и размеры шрифтов общеизвестно. Кроме того, пользователь может изменить размеры окна браузера после загрузки страницы, так что пришлось бы переформатировать текст js скриптом по OnResize.
Очевидно, необходим более гибкий и аккуратный метод. Посмотрим, что нам предлагают авторы браузеров и стандартов.
Microsoft предлагает хороший способ:
<P STYLE="word-wrap:break-word;width:100%;left:0">
LongWordLongWord...LongWordLongWord</P>
Или, если надо разрешить разрывы слов только на конкретном участке:
<P>LongWordLongWord...<span STYLE="word-wrap:break-word;width:100%;left:0">LongWordLongWord---LongWord</span>::LongWordLongWord,,,LongWordLongWord</P>
(знаки препинания вставлены произвольно)
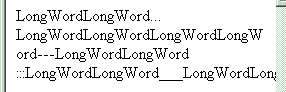
word-wrap:break-word; в MSIE5.5. Видно, что
на участке ограниченном <span></span>
браузер разорвал слово и перенес его.
Однако за пределами этого участка текст
переносится как обычно - по пробелам.
В этом параграфе слово будет разбито автоматически. Одно плохо - метод работает только в MSIE 5.5 и выше (проверено в 5.5 и 6.0).
Будем смотреть дальше:
В стандарте на HTML 4 существует символ "­" - так называемый "мягкий перенос". Вообще же, это стандартный символ в Unicode и Latin-1 который Windows знает, но не всегда любит [правильно] показывать.
Если его вставить в слово, например так:
LongWordLongWord­LongWordLongWord
..то браузер в нормальных условиях этот символ не отобразит вообще. Однако, если места для слова не хватает, в этом месте оно должно быть автоматически перенесено на следующую строчку и появится знак переноса "-". Я говорю должно быть, поскольку браузеры - не всегда отражение стандарта на HTML.

действие ­ в MSIE 5.0.x
Под MSIE 5.0.x все с виду работает, но в определенные моменты (при изменении размера окна браузера) определенные слова вдруг оказываются разбиты черточками без всякой на то видимой причины.
NS 4.05/Win32, NS4.7/Win32 и вовсе показывает дефисы во всех словах, независимо ни от чего.
В MSIE6 работает нормально.
В NS4.7/FreeBSD, NS6.0/Win32 не работает.
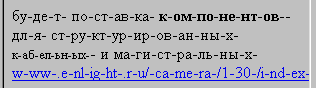
а вот так понимает ­ NS 4.05 и 4.7
Помимо прочего, если поместить разбитую таким образом строчку в clipboard, а затем извлечь обратно - невидимые переносы превратятся в банальные "-". Это произойдет например в ICQ2000, GoldED 3.0.1/Win32, EditPlus. А Outlook и WinWord с одной стороны воспринимают "­" правильно, но с другой ведут себя с такими строчками немного странно.
Очевидно, этот метод далек от совершенства - надо думать дальше.
Если копнуть глубже, в черновом варианте стандарта HTML 3.2
упоминались применительно к Netscape
любопытные тэги: <nobr> и <wbr>.
Тэгами <nobr></nobr> ограничивался участок текста, который браузер не имел права разбивать.
<wbr> напротив - указывал место, в котором слово можно было переносить на другую строчку.
Однако, со времен HTML3.2 утекло много воды и эти тэги стали (говорю после общения с www.google.com) всенародно любимыми, но официально презираемыми. Впрочем, поддержка в браузерах осталась. Но работает странно - видимо, она отражает представление разных групп разработчиков о вселенной :)

действие тэга <wbr> в MSIE 5.0.x
В MSIE 5.0.x и NS 4.05 необходимо писать так:
<NOBR>LongWordLongWord<WBR>LongWordLongWord</NOBR>
А вот в NS 6.x только так:
LongWordLongWord<WBR>LongWordLongWord
причем если добавить <NOBR> - работать перестает.
В NS 4.7/Win32 и в MSIE6/Win32 работают оба варианта.
В NS4.7/FreeBSD не работает ни один.
Выводы из этой грустной истории такие:
Можно ждать, когда все перестанут пользоваться старыми браузерами, а новые поголовно начнут поддерживать
­ (и не переносить его в
clipboard в виде дефисов).
Можно комбинировать ­ с
<WBR> (именно в таком порядке):
LongWordLongWord­<WBR>LongWordLongWord
Другой вариант (возможно - лучший) - определять тип браузера и взависимости от этого генерировать текст с разбивкой нужными тэгами. Я написал для этого небольшую PHP функцию, возможно кому-то она будет полезна, после усовершенствования:
# -----------------------------------------------------------------------------
# Если в строке $s встречается слово (последовательность символов без пробелов)
# длиннее чем $wordmaxlen , оно ограничивается тэгами $leftlimit, $rightlimit и
# разбивается тэгами $hyp на несколько слов, каждое из которых не
# длиннее $wordmaxlen. Тэги бывшие в $s изначально - не затрагиваются.
#
# Примеры:
# ($s,2,'<nobr>','</nobr>','<wbr>')
# ($s,2,'','','<wbr>')
# ($s,2,'','','­')
# ($s,2,'','','­<wbr>')
# -----------------------------------------------------------------------------
function SplitText($s,$wordmaxlen,$leftlimit,$rightlimit,$hyp)
{
$marker = "\x01";
# Сохраняем все тэги чтобы уберечь их от разбивки
preg_match_all('/(<.*?\>)/si',$s,$tags);
# Заменяем все тэги на маркеры
$s = preg_replace('/(<.*?\>)/si', $marker, $s);
# Разбиваем текст на слова
$words = split(' ',$s);
for ($i=0; $i<count($words); $i++)
{
# Каждое слово >= $wordmaxlen разбиваем
if (strlen($words[$i])>=$wordmaxlen)
$words[$i] = $leftlimit . chunk_split($words[$i],$wordmaxlen,$hyp) . $rightlimit;
}#for
# Собираем строку из уже разбитых на части слов
$s = implode(' ',$words);
# Восстанавливаем тэги, места которых были отмечены маркерами
for ($i=0; $i<count($tags[1]); $i++)
$s = preg_replace("/$marker/si", $tags[1][$i], $s, 1);
return $s;
}#SplitText
Из остальных браузеров которые были под рукой: Opera 4.02, 5.12 вообще игнорирует все перечисленные способы. Lynx 2.8.4pre.5 напротив - поддерживает все, кроме варианта с "word-wrap:break-word;".
Хотя идеального решения проблемы не найдено, но, надеюсь, кому-то я сберег время и нервы. Или наоборот - расшатал :)
Что можно сказать в итоге? Все мы не питаем особой любви к Microsoft и другим крупным корпорациям-монополиям.
Однако, с точки зрения стандартизации, конкуренция - не самое полезное явление. Странная и безвыходная (казалось бы) получается ситуация:
Если фирма укрупняется - получаем монополию, которая творит что ей вздумается,
однако поддерживает стандарты, имеет
возможность проводить серьезные (требующие капиталовложений) исследования.
Если разбиваем монополию на мелкие фирмы - они начинают конкурировать между собой, придумывать в пику друг другу разные тэги, торопятся выкатывать сырые и громоздкие продукты из боязни, что сосед выкатит свой продукт первым..
Может, плоха не монополия, а то, что она существует для своих владельцев, а не для заинтересованного в стандартах и прогрессе общества?
(Благодарности: Theta, Riddle,
AngelDust)
 "Finally, we come to the instruction we've all been waiting for – SEX!" / из статьи про микропроцессор CDP1802 / В начале 1970-х в США были весьма популярны простые электронные игры типа Pong (в СССР их аналоги появились в продаже через 5-10 лет). Как правило, такие игры не имели микропроцессора и памяти в современном понимании этих слов, а строились на жёсткой ...далее
"Finally, we come to the instruction we've all been waiting for – SEX!" / из статьи про микропроцессор CDP1802 / В начале 1970-х в США были весьма популярны простые электронные игры типа Pong (в СССР их аналоги появились в продаже через 5-10 лет). Как правило, такие игры не имели микропроцессора и памяти в современном понимании этих слов, а строились на жёсткой ...далее